De Wayback Machine is een gratis digitaal archief waarmee je oude versies van websites kunt bekijken. Het laat je terugreizen in de tijd: plak een URL in de zoekbalk, kies een datum, en je ziet precies hoe die pagina er jaren geleden uitzag. The Wayback Machine is een onderdeel van het Internet Archive, een non-profitorganisatie uit San Francisco die sinds 1996 miljarden webpagina's bewaart. Of je nu een verdwenen artikel zoekt, bewijs nodig hebt van wat er ooit op een site stond, of gewoon nieuwsgierig bent naar het vroege web — dit is de tool die het mogelijk maakt.
Hoe groot dat archief inmiddels is, geeft de schaal goed weer: in oktober 2025 passeerde de Wayback Machine een biljoen (1.000 miljard) gearchiveerde webpagina's, goed voor meer dan 99 petabyte aan data (Internet Archive).
In dit artikel leg ik uit wat de Wayback Machine precies is, hoe het web archive werkt, hoe je de Wayback Machine gebruikt om oude websites terug te vinden, en hoe je zelf webpagina's kunt archiveren. Ook bespreek ik de beperkingen, want niet alles laat zich even goed vastleggen.
Wat is de Wayback Machine?
De Wayback Machine is een doorzoekbaar archief van het World Wide Web. Het bewaart kopieën van websites — snapshots genoemd — zodat je kunt zien hoe een pagina er op een bepaald moment uitzag. Sinds de lancering in 2001 (op basis van data die al vanaf 1996 werd verzameld) is het uitgegroeid tot het grootste publieke internetarchief ter wereld, met honderden miljarden gearchiveerde pagina's.
Het project is bedacht door Brewster Kahle, die ook het Internet Archive oprichtte. Het idee was simpel maar ambitieus: het web verandert constant, pagina's verdwijnen, en zonder archief gaat die geschiedenis verloren. Het Internet Archive — gevestigd in San Francisco — zette zich als non-profitorganisatie de taak om het web systematisch te bewaren. The Internet Archive's Wayback Machine is daarvan het bekendste onderdeel.
Belangrijk om te begrijpen: de Wayback Machine bewaart geen live kopie, maar momentopnames. Elke keer dat een pagina wordt gearchiveerd, ontstaat er een nieuwe versie in het archief. Zo kun je voor populaire sites tientallen of zelfs honderden versions van dezelfde URL terugvinden, elk vastgelegd op een ander moment.
Hoe werkt het web archive?
Het archiveren gebeurt op twee manieren. Het grootste deel verloopt automatisch: software die crawlers heet, bezoekt doorlopend het web en maakt kopieën van de pagina's die het tegenkomt. Die crawlers volgen links van URL naar URL en leggen onderweg snapshots vast, die vervolgens worden opgeslagen in het archief van het Internet Archive.
Daarnaast kun je zelf een capture starten. Met de "Save Page Now"-functie geef je het archief opdracht om een specifieke web page op dit moment vast te leggen. Dat is handig wanneer je zeker wilt weten dat een belangrijke pagina bewaard blijft voordat hij verandert of offline gaat. Achter de schermen draait dit alles op de infrastructuur van het Internet Archive, met een eigen content delivery network om de enorme hoeveelheid gearchiveerde data wereldwijd uit te serveren.
De technische opzet betekent ook dat een gearchiveerde pagina niet altijd identiek is aan het origineel. De Wayback Machine slaat de HTML, afbeeldingen en stylesheets op zoals ze op het moment van archiveren beschikbaar waren. Voor wie het op grote schaal nodig heeft, biedt het Internet Archive bovendien een API waarmee je geautomatiseerd requests kunt doen naar het archief.
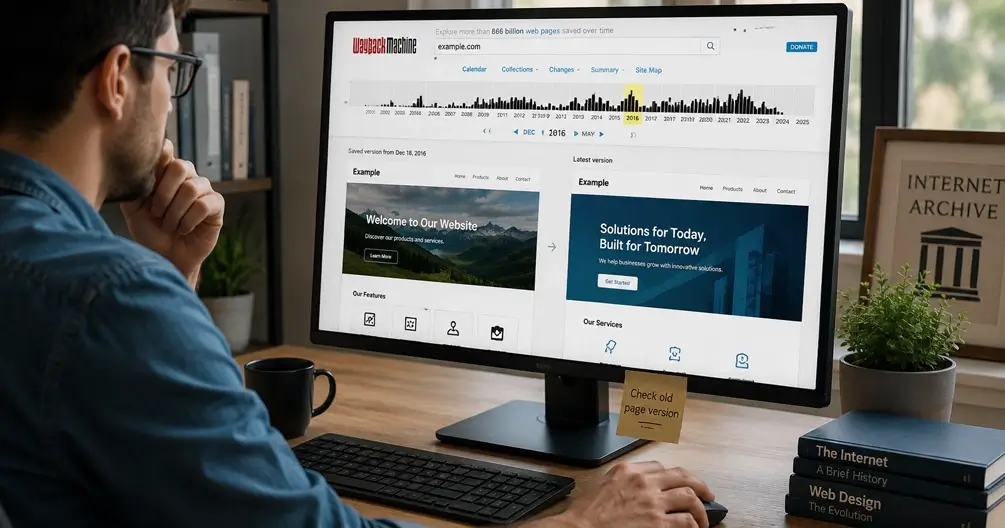
De Wayback Machine gebruiken: oude versies van websites bekijken
De Wayback Machine gebruiken is eenvoudiger dan je denkt. In een paar stappen bekijk je hoe een willekeurige website er vroeger uitzag:
- Ga naar archive.org/web — de startpagina van The Wayback Machine, te openen in elke browser
- Voer de URL in — plak het webadres van de site die je wilt onderzoeken in de zoekbalk en bevestig de search
- Kies een datum — je krijgt een kalender (a calendar) te zien met alle momenten waarop er een snapshot van die pagina is gemaakt
- Bekijk de gearchiveerde versie — klik op een gemarkeerde dag en je ziet hoe de pagina er op dat moment uitzag
De kalender is het hart van de ervaring. Hoe vaker een site werd bezocht door de crawlers, hoe meer Wayback Machine snapshots je terugvindt. Voor een grote nieuwssite kun je vrijwel elke dag een versie opvragen; voor een kleine, vergeten website zijn er misschien maar een handvol kopieën. Kies een datum en je reist terug naar precies dat moment — soms tot ruim twintig jaar geleden.
Dit maakt de tool waardevol in allerlei situaties: een verdwenen blogpost terugvinden, controleren wat een concurrent vroeger op zijn site beweerde, een oude prijslijst opzoeken, of bewijs bewaren van content die later is aangepast — bijvoorbeeld tijdens de due diligence wanneer je een bestaande website wilt overnemen. Alles wat ooit publiekelijk online stond en door het archief is vastgelegd, kun je via de Wayback Machine terughalen — net als de history van een website die te koop staat.
Zelf webpagina's archiveren met Save Page Now
Je hoeft niet te wachten tot de crawlers langskomen — je kunt zelf webpagina's archiveren. De functie "Save Page Now" op archive.org legt elke publieke URL direct vast in het web archive. Je plakt het adres, klikt op de knop, en binnen enkele seconden bestaat er een permanente, gearchiveerde kopie van die pagina.
Dit is vooral nuttig om je eigen content veilig te stellen of om iets vast te leggen voordat het verdwijnt. Wil je het nog makkelijker maken, dan zijn er browserextensies — bijvoorbeeld voor Chrome — die een knop aan je toolbar toevoegen waarmee je met één klik een pagina kunt archiveren of de gearchiveerde versie ervan kunt openen. Zo archiveer je een page zonder telkens naar de site van het archief te gaan.
Voor wie veel URLs tegelijk wil vastleggen, biedt de Save Page Now API uitkomst. Daarmee stuur je geautomatiseerd verzoeken om pagina's te laten archiveren — handig voor onderzoekers, journalisten of bedrijven die structureel kopieën van websites willen bewaren.
De beperkingen van de Wayback Machine
Hoe krachtig het archief ook is, het is niet alomvattend. Niet elke pagina wordt vastgelegd, en wat wél is opgeslagen, is niet altijd compleet. De belangrijkste beperkingen:
- JavaScript-zware sites — content die volledig met JavaScript wordt ingeladen, wordt vaak niet of niet correct gearchiveerd; de Wayback Machine legt het beste statische HTML vast
- Afgeschermde pagina's — sites die archivering blokkeren via robots.txt of een login vereisen, belanden meestal niet in het archief
- Gaten in de tijdlijn — kleine of weinig bezochte sites worden zelden gecapt, dus er kunnen lange periodes zonder snapshots zijn
- Gebroken weergave — soms ontbreken afbeeldingen of styling omdat die op het moment van archiveren niet werden meegenomen
Houd er dus rekening mee dat een gearchiveerde versie een benadering is van het origineel, geen perfecte cached kopie. Voor tekstuele content is de Wayback Machine doorgaans uitstekend; voor interactieve, JavaScript-gedreven applicaties is het resultaat wisselend.
Veelgestelde vragen
Wat is de Wayback Machine?
De Wayback Machine is een gratis online archief dat oude versies van websites bewaart. Het is een onderdeel van het Internet Archive, een non-profitorganisatie uit San Francisco. Sinds 1996 maken crawlers automatisch snapshots van webpagina's, zodat je kunt zien hoe een pagina er op een bepaald moment uitzag — soms tot meer dan twintig jaar geleden.
Hoe gebruik ik de Wayback Machine?
Ga naar archive.org/web, plak de URL van de website in de zoekbalk en kies een datum in de kalender. De Wayback Machine toont dan de gearchiveerde versie van die pagina op dat moment. Wil je zelf een pagina vastleggen, gebruik dan de "Save Page Now"-functie om direct een snapshot te maken.
Kan ik mijn eigen website laten archiveren?
Ja. Met "Save Page Now" op archive.org leg je elke publieke URL handmatig vast in het web archive. Daarnaast bezoeken de crawlers van het Internet Archive het web doorlopend en archiveren ze veel pagina's automatisch. Houd er rekening mee dat content die volledig met JavaScript wordt geladen niet altijd correct wordt opgeslagen.
Is de Wayback Machine gratis?
Ja, de Wayback Machine en het hele Internet Archive zijn gratis te gebruiken. De organisatie is een non-profit en draait grotendeels op donaties. Je hebt geen account nodig om oude versies van websites te bekijken; alleen voor sommige functies, zoals het opslaan van een pagina, log je optioneel in.
Kernpunten
- De Wayback Machine is een gratis archief van oude versies van websites, onderdeel van het Internet Archive in San Francisco
- Het bewaart snapshots van webpagina's, die automatisch door crawlers en handmatig via "Save Page Now" worden vastgelegd
- Je gebruikt het door een URL in te voeren, een datum in de kalender te kiezen en de gearchiveerde versie te bekijken
- Met Save Page Now en de API kun je zelf webpagina's archiveren en kopieën van websites veiligstellen
- De grootste beperking is JavaScript-zware content, die niet altijd correct in het archief belandt
Wil je het zelf proberen, begin dan klein: open archive.org/web in je browser, plak de URL van je eigen website en kijk hoe die er een paar jaar geleden uitzag. Leg vervolgens je belangrijkste pagina's vast met "Save Page Now", zodat er altijd een gearchiveerde versie bestaat — handig als bewijs of als back-up wanneer een site ooit offline gaat. Het web vergeet snel; de Wayback Machine zorgt dat jij dat niet hoeft te doen.