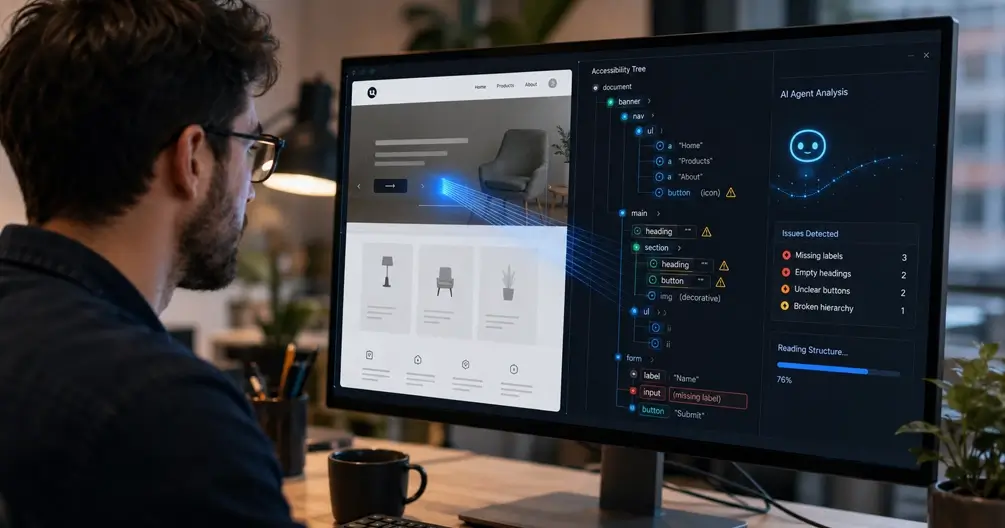
AI-agents lezen jouw website niet zoals jij hem ziet. Geen screenshots, geen mooi design — ze lezen de accessibility tree, dezelfde semantische structuur die screenreaders al jaren gebruiken. En precies die structuur loopt op grote schaal stuk: volgens het WebAIM Million-rapport heeft 95,9% van de grootste websites detecteerbare toegankelijkheidsfouten. Nu geautomatiseerd verkeer dat van mensen heeft ingehaald, is dat geen compliance-bijzaak meer — het is je primaire interface.
In dit artikel lees je wat de accessibility tree is, waarom AI-agents hem verkiezen boven een screenshot, waarom hij juist nu kapotgaat, en — concreet — hoe je je website leesbaar maakt voor zowel mensen als machines.
Wat is de accessibility tree?
De accessibility tree is een semantisch structuurmodel dat de browser uit de DOM opbouwt. In de woorden van het W3C is het "een boom van toegankelijke objecten die de structuur van de gebruikersinterface representeert". Hij toont geen pixels of opmaak, maar reduceert de pagina tot wat betekenis draagt: koppen, links, knoppen, formuliervelden, landmarks en afbeeldingen met tekstalternatief.
Elke node draagt vier eigenschappen:
- Role — wat het element is (knop, navigatie, lijstitem)
- Name — hoe ernaar verwezen wordt ("Lees meer", "Verstuur")
- State — de huidige toestand (aangevinkt, uitgeschakeld, uitgeklapt)
- Description — extra context, zoals een tooltip
Voor een mens met een screenreader is dit de website. En sinds AI-agents het web bezoeken, geldt dat voor hen net zo goed.
Waarom AI-agents de accessibility tree lezen
AI-agents verkiezen de accessibility tree boven een screenshot om twee nuchtere redenen. Ten eerste de kosten: een screenshot door een visiemodel laten interpreteren kost veel tokens. Ten tweede de betrouwbaarheid: de tree vermeldt expliciet wat klikbaar is en wat een element doet, in plaats van een model te dwingen dat uit beeld te raden.
Het is geen theorie. Microsoft's Playwright werkt bewust met de accessibility tree en noemt een toegankelijkheidssnapshot "beter dan een screenshot". OpenAI geeft aan dat zijn agent-omgeving dezelfde ARIA-labels en rollen gebruikt die ook screenreaders ondersteunen. De agents leunen dus op exact dezelfde semantiek als toegankelijkheidssoftware.
En de timing maakt het urgent. Volgens data van Cloudflare maakten geautomatiseerde bots in juni 2026 57,2% van al het HTML-verkeer uit — meer dan de 42,8% van mensen. Een groeiend deel van je publiek leest letterlijk je accessibility tree in plaats van je vormgeving.
Waarom het stukloopt
Hier wordt het ongemakkelijk. Het WebAIM Million-rapport van 2026, dat de homepages van de grootste miljoen websites analyseert, laat zien dat toegankelijkheid juist achteruitgaat:
- 95,9% van de homepages heeft detecteerbare WCAG-fouten (was 94,8% in 2025)
- 56,1 fouten per pagina gemiddeld — 10,1% meer dan de 51 van 2025
- 1.437 elementen per homepage, een toename van 22,5% in één jaar
Daarmee keert de trend van zes jaar kleine verbeteringen om. WebAIM wijst naar een oorzaak die elke developer herkent: meer leunen op externe frameworks en libraries, en op geautomatiseerd of AI-ondersteund coderen ("vibe coding"). Meer code, sneller verscheept, met minder menselijke review — en dus opgeblazen DOM's en kapotte semantiek.
De fouten die agents het hardst raken:
| Fout | Komt voor op | Gevolg voor agents |
|---|---|---|
| Tekst met te weinig contrast | 83,9% | visiemodellen kunnen het niet lezen |
| Ontbrekende alt-tekst | 53,1% | afbeelding draagt geen betekenis |
| Ontbrekende formulierlabels | 51% | velden niet aan een doel te koppelen |
| Lege links | 46,3% | node met rol maar zonder naam |
| Lege knoppen | 30,6% | besturing die de agent ziet maar niet kan duiden |
Bijna de helft van de grootste sites heeft lege links; een derde heeft lege knoppen. Voor een agent zijn dat doodlopende wegen.
De ARIA-paradox
Tegen de intuïtie in maakt méér ARIA het vaak slechter. Pagina's die ARIA gebruiken hadden volgens WebAIM gemiddeld 59,1 fouten, tegenover 42 op pagina's zonder. Het probleem: onjuiste ARIA-attributen misleiden agents door ze met stelligheid de verkeerde informatie te geven.
De eerste regel van ARIA, van het W3C, is daarom glashelder: "als je een native HTML-element kunt gebruiken in plaats van een element te herbestemmen en er een ARIA-rol aan toe te voegen, doe dat dan". Toegankelijkheidsspecialisten zeggen het al jaren: repareer eerst je native markup, plak er geen attributen overheen. De data geeft ze gelijk — de pagina's die het hardst naar ARIA grijpen, dragen de meeste fouten.
Voor de machine zijn toegankelijkheid en leesbaarheid hetzelfde probleem
Dit is de kern. Semantische HTML — een echte semantische HTML-structuur met <button>, <a href>, <label> en <select> — levert vanzelf de juiste rollen en namen op. Een <button> verschijnt zonder extra werk in de tree; een <div> met een klik-handler verschijnt als een naamloze, rolloze node die een agent niet kan vertrouwen.
Dezelfde defecten die een screenreader breken, breken een AI-agent. Toegankelijkheidsstandaarden zoals WCAG bepalen wat content machineleesbaar maakt, en AI-leesbaarheid leunt volledig op dat fundament. Het is dezelfde discipline die ook je gestructureerde data en je Core Web Vitals op orde houdt: techniek die machines helpt je site te begrijpen. En het sluit aan op een bredere verschuiving die we eerder beschreven rond AI in de zoekresultaten: wie gevonden wil worden door AI, moet door AI gelezen kunnen worden.
Hoe je je website leesbaar maakt voor AI-agents
Het goede nieuws: de oplossingen zijn onspannend en bekend. Geen nieuwe tool-stack, gewoon vakwerk.
- Gebruik native HTML voor native gedrag. Een
<button>in plaats van een<div onclick>, een<a href>in plaats van een JavaScript-link, een<label>bij elk formulierveld. - Geef elke besturing een naam. Toegankelijke tekst op alle links en knoppen, ook de icon-only varianten, en echte labels op elk invoerveld.
- Server-render je kritieke content. Prijzen, specificaties en primaire acties moeten server-side aanwezig zijn; content die alleen via client-side JavaScript verschijnt, bereikt de tree die agents lezen mogelijk nooit.
- Reserveer ARIA voor echte gaten. Eerst correcte semantiek, dan pas attributen — en alleen waar native HTML een toestand niet kan uitdrukken.
- Controleer het resultaat. Gebruik de "Show accessibility tree"-optie in Chrome DevTools of de ARIA-snapshots van Playwright om te verifiëren dat elke belangrijke actie een duidelijke rol én naam heeft.
Het mooie is dat dit dubbel rendeert: dezelfde ingrepen maken je site toegankelijker voor mensen met een beperking én leesbaarder voor de agents die een steeds groter deel van je verkeer vormen. Eén investering, twee publieken.
Veelgestelde vragen
Wat is de accessibility tree?
De accessibility tree is een semantisch model dat de browser uit de DOM opbouwt en de pagina beschrijft in een vorm die niet-visuele software begrijpt. In plaats van pixels en layout bevat hij de betekenisvolle elementen — koppen, links, knoppen, formuliervelden en afbeeldingen met alt-tekst — elk met een rol, naam, status en beschrijving. Screenreaders gebruiken hem al jaren, en AI-agents nu ook.
Waarom lezen AI-agents de accessibility tree in plaats van een screenshot?
Omdat het goedkoper en betrouwbaarder is. Een screenshot kost veel tokens om door een visiemodel te laten interpreteren, terwijl de accessibility tree expliciet vermeldt wat klikbaar is en wat een element doet. Tools als Microsoft Playwright en OpenAI's agent-omgevingen leunen daarom op de tree en ARIA-labels in plaats van op beeldherkenning.
Waarom is dit nu zo belangrijk geworden?
Omdat geautomatiseerd verkeer mensen heeft ingehaald. Volgens Cloudflare maakten bots in juni 2026 57,2% van al het HTML-verkeer uit, tegenover 42,8% mensen. Tegelijk laat het WebAIM Million-rapport zien dat 95,9% van de grote sites toegankelijkheidsfouten heeft. Steeds meer van je publiek leest dus je accessibility tree in plaats van je design — en die loopt massaal stuk.
Moet ik overal ARIA aan toevoegen om AI-leesbaar te zijn?
Nee, juist niet. Onderzoek van WebAIM laat zien dat pagina's mét ARIA gemiddeld méér fouten hebben dan pagina's zonder, omdat verkeerde ARIA-attributen agents zelfverzekerd de verkeerde kant op sturen. De eerste regel van ARIA luidt: gebruik native HTML als dat kan. Repareer eerst je semantiek, en zet ARIA alleen in waar native HTML een toestand echt niet kan uitdrukken.
Kernpunten
- AI-agents lezen je site via de accessibility tree (rol, naam, status, beschrijving), niet via screenshots — net als screenreaders
- Bots zijn mensen voorbij: 57,2% van het HTML-verkeer is geautomatiseerd (Cloudflare, juni 2026)
- Toegankelijkheid gaat juist achteruit: 95,9% van de grote sites heeft WCAG-fouten, mede door frameworks en "vibe coding" (WebAIM Million 2026)
- Meer ARIA is niet beter: foute ARIA misleidt agents — gebruik eerst native HTML (eerste regel van ARIA, W3C)
- Fix het met vakwerk: native HTML, namen op elke besturing, server-rendered kritieke content en controle via de accessibility tree in DevTools/Playwright
Open vandaag nog je eigen site in Chrome DevTools en zet "Show accessibility tree" aan. Klik door je belangrijkste acties — je hoofdnavigatie, je call-to-action, je formulieren — en kijk of elke node een duidelijke rol én naam heeft. Vind je lege knoppen, naamloze links of content die alleen client-side verschijnt, dan kijk je naar precies de plekken waar AI-agents (en screenreaders) vastlopen. Het oplossen ervan is geen hype-project, maar het soort fundament dat zowel je toegankelijkheid als je vindbaarheid in het AI-tijdperk draagt. Sparren over de techniek? Dat doe je op het development-forum van CreativeDeals.